What is CherryTrail (Braswell)?
“CherryTrail” (CYT) is the next generation Atom “APU” SoC from Intel (v3 2015) replacing the current Z3000 “BayTrail” (BYT) SoC which was Intel’s major foray into tablets (both Windows & Android). The “desktop” APUs are known as “Braswell” (BRS) while the APUs for other platforms have different code names.
BayTrail was a major update both CPU (OOS core, SSE4.x, AES HWA, Turbo/dynamic overclocking) and GPU (EV7 IvyBridge GPGPU core) so CherryTrail is a minor process shrink – but with a very much updated GPGPU – updated to EV8 (as latest Core Broadwell).
In this article we test (GP)GPU graphics unit performance; please see our other articles on:
Hardware Specifications
We are comparing Atom processors with the Core M processors. New models may run at higher (or lower) frequencies than the ones they replace, thus performance delta can vary.
| APU Specifications | Atom Z3770 (BayTrail) | Atom X7 Z8700 (CherryTrail) | Core M 5Y10 (Broadwell-Y) | Comments | |
| Cores (CU) / Threads (SP) | 4C / 4T | 4C / 4T | 2C / 4T | The new Atom still has 4C and no HT same as the old Atom; Core M has 2 cores but with HT so still 4 threads in total – we shall see whether this makes a big difference. | |
| Speed (Min / Max / Turbo) | 533-1467-2400 (6x-11x-18x) | 480-1600-2400 (6x-20x-30x) | 500-800-2000 (5x-8x-20x) | The new CherryTrail Atom has lower BCLK (80MHz) compared to BayTrail (133MHz) and thus higher multipliers while LFM (Low), MFM (Rated) and Turbo (TFM) speeds are very similar. | |
| Power (TDP) | 2.4W | 2.4W | 4.5W | TDP remains the same for the new Atom while Core M needs around 2x (twice) as much power. | |
| L1D / L1I Caches | 4x 24kB 6-way / 4x 32kB 8-way | 4x 24kB 6-way / 4x 32kB 8-way | 2x 32kB 8-way / 2x 32kB 8-way | No change in L1 caches on the new Atom; comparatively Core M has half the caches. | |
| L2 Caches | 2x 1MB 16-way | 2x 1MB 16-way | 4MB 16-way | No change in L2 cache; here Core M has twice as much cache – same size as a normal i7 ULV. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Haswell introduces AVX2 which allows 256-bit integer SIMD (AVX only allowed 128-bit) and FMA3 – finally bringing “fused-multiply-add” for Intel CPUs. We are now seeing CPUs getting as wide a GP(GPUs) – not far from AVX3 512-bit in “Phi”.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 8.1 x64, latest Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | Atom Z3770 (BayTrail) | Atom X7 Z8700 (CherryTrail) | Core M 5Y10 (Broadwell-Y) | Comments | |
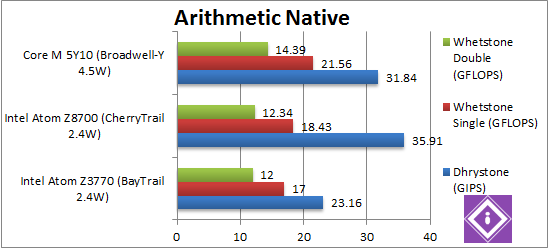 |
|||||
 |
Native Dhrystone (GIPS) | 15.11 SSE4 | 35.91 SSE4 [+55%] | 31.84 AVX2 [-12%] | CherryTrail has no AVX2 but manages to be 55% faster than old Atom and even a big faster than Core M with AVX2! A great start! |
|
Native FP32 (Float) Whetstone (GFLOPS) | 11.09 AVX | 18.43 AVX [+8.4%] | 21.56 AVX/FMA [+17%] | CherryTrail has no FMA either, but here it is only 8% faster than old Atom. Core M does better here – it’s 16% faster still. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 8.6 AVX | 12.34 AVX [+2.8%] | 13.49 AVX/FMA [+17%] | With FP64 we see and even smaller 3% gain. Core M remains 16% faster still. |
| We see a big improvement with integer workload of 50% but minor 3-8% with floating-point. Sure Core M is faster (16%) but not by a huge amount to justify power and cost increase. | |||||
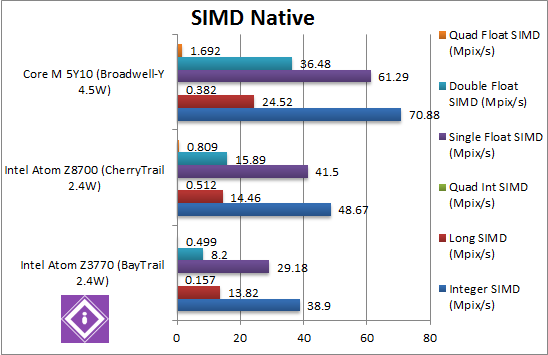 |
|||||
 |
Native Integer (Int32) Multi-Media (Mpix/s) | 25.1 AVX | 48.7 AVX [+25%] | 70.8 AVX2 [+45%] | Again CherryTrail has to do without AVX2, but is still 25% faster than old Atom – a decent improvement. Here though AVX2 of Core M has a sizeable 45% improvement. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 9 AVX | 14.5 AVX [+4.6%] | 24.5 AVX2 [+69%] | With a 64-bit integer workload, the improvement drops to about 5%. Here Core M with AVX2 is 70% faster still – finally a big improvement over Atom. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 0.109 | 0.512 [+3.3x] | 0.382 [-25%] | This is a tough test using Long integers to emulate Int128, but here CherryTrail manages to be over 3x faster than old Atom – and even faster than Core M! Without SIMD the new Atom does much better than even Core M. |
|
Native Float/FP32 Multi-Media (Mpix/s) | 18.9 AVX | 41.5 AVX [+42%] | 61.3 FMA [+47%] | In this floating-point AVX/FMA algorithm, CherryTrail does much better returning with a 42% improvement over old Atom. Core M also returns to a 47% improvement still – seems to be the par for SIMD ops. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 8.18 AVX | 15.9 AVX [+93%] | 36.48 FMA [+2.3x] | Switching to FP64 code, CherryTrail is now almost 2x as fast as old Atom – with Core M being over 2x faster still. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 0.5 AVX | 0.81 AVX [+62%] | 1.69 FMA [+2.1x] | In this heavy algorithm using FP64 to mantissa extend FP128, CherryTrail manages a 62% improvement and again Core M is over 2x still. |
| Lack of AVX2/FMA and higher Turbo speed prevents the new Atom from crushing the old Atom – but still allows a 25-100% (2x as fast) improvement, a significant improvement. Here, though, with AVX2 and FMA – Core M is 45-100% faster still thus could be worth it if more compute power is required. | |||||
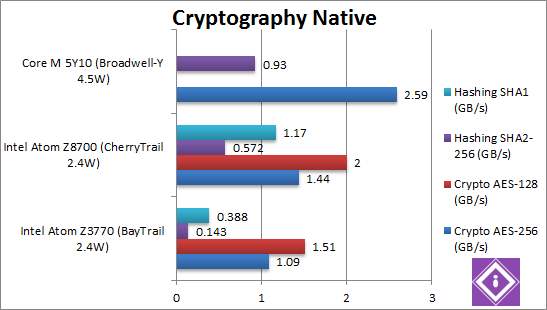 |
|||||
 |
Crypto AES-256 (GB/s) | 1.09 AES HWA | 1.44 AES HWA [+32%] | 2.59 AES HWA [+79%] | All three CPUs support AES HWA – thus it is mainly a matter of memory bandwidth – here CherryTrail is 32% faster – thus we’d predict its memory controller can yield +35% more bandwidth. But even with just half no. cores Core M is 80% faster still – likely due to its dual-channel controller. |
|
Crypto AES-128 (GB/s) | 1.51 AES HWA | 2 AES HWA [+32%] | ? AES HWA | What we saw with AES-256 was no fluke: less rounds don’t make any difference, new Atom is 32% faster. |
|
Crypto SHA2-256 (GB/s) | 0.143 AVX | 0.572 AVX [+4x] | 0.93 AVX2 [+63%] | SHA HWA will come for the next Atom arch, so neither CPU supports it. But CherryTrail can manage to be a whopping 4x (four times) faster than old Atom. But Core M with AVX2 still manages to be 63% faster. |
|
Crypto SHA1 (GB/s) | 0.388 AVX | 1.17 AVX [+3x] | ? AVX2 | With a less complex algorithm – we see a 3x (three times) improvement over old Atom. |
| CherryTrail still misses AVX2 or forthcoming SHA HWA – but due to (expected) higher memory bandwidth it still improves over old Atom – while raw compute is 3-4x faster – a huge improvement. Due to its dual-channel controller and AVX2 Core M is still faster than it by a good 60-80%. | |||||
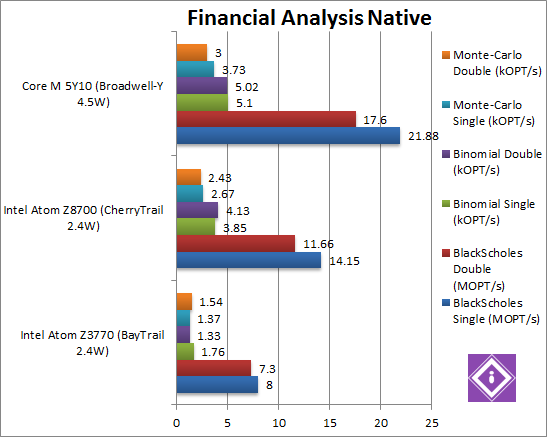 |
|||||
 |
Black-Scholes float/FP32 (MOPT/s) | 8.0 | 14.15 [+76%] | 21.88 [+54%] | In this non-SIMD test we start with a good 76% improvement over old Atom – while Core M is 50% faster still. CherryTrail shows its prowess in FPU processing. |
|
Black-Scholes double/FP64 (MOPT/s) | 7.3 | 11.66 [+59%] | 17.6 [+50%] | Switching to FP64 code, CherryTrail is still 60% faster – and Core M remains 50% faster still. |
|
Binomial float/FP32 (kOPT/s) | 1.76 | 3.85 [+2.2x] | 5.1 [+32%] | Binomial uses thread shared data thus stresses the cache & memory system; CherryTrail is over 2x (twice) as fast as old BayTrail – with Core M just 32% faster. It seems the new memory improvements do help a lot. |
|
Binomial double/FP64 (kOPT/s) | 1.33 | 4.13 [+3.1x] | 5.02 [+21%] | With FP64 code CherryTrail is now a whopping 3x (three times) faster – a massive improvement. Core M is just 20% faster still. |
|
Monte-Carlo float/FP32 (kOPT/s) | 1.37 | 2.67 [+94%] | 3.73 [+39%] | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; CherryTrail remains about 2x faster than old Atom – showing just how much the memory improvements help. Core M is still 40% faster. |
|
Monte-Carlo double/FP64 (kOPT/s) | 1.54 | 2.43 [+57%] | 3.0 [+23%] | Switching to FP64 the improvement drops to around 60% – still a big improvement. Core M’s improvement drops to 23%. |
| The financial tests show big improvements of 60-200% – complex compute tasks are now very much possible on Atom. Without help from AVX2 and FMA – Core M can only be 20-50% faster still, not the improvement we were hoping. | |||||
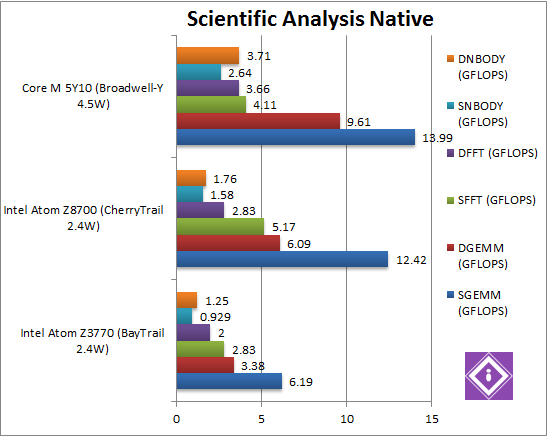 |
|||||
 |
SGEMM (GFLOPS) float/FP32 | 6.19 AVX | 12.42 AVX [+2x] | 13.99 FMA [+12%] | In this tough SIMD algorithm, again CherryTrail manages to be 2x as fast as old Atom; even with the help of FMA, Core M is only 12% faster. The new Atom is just running away with it. |
|
DGEMM (GFLOPS) double/FP64 | 3.38 AVX | 6.09 AVX [+80%] | 9.61 FMA [+58%] | With FP64 SIMD code, CherryTrail remains about 80% faster, just under 2x. Here Core M shows its power, it’s almost 60% faster still. |
|
SFFT (GFLOPS) float/FP32 | 2.83 AVX | 5.17 AVX [+82%] | 4.11 FMA [-21%] | FFT also uses SIMD and thus AVX but stresses the memory sub-system more: CherryTrail remains 82% faster than old Atom and here it beats even Core M. |
|
DFFT (GFLOPS) double/FP64 | 2 AVX | 2.83 AVX [+41%] | 3.66 FMA [+29%] | With FP64 code, the improvement is reduced to just 41% but it is still significant. Core M’s improvement drops to just 30%. |
|
SNBODY (GFLOPS) float/FP32 | 0.929 AVX | 1.58 AVX [+70%] | 2.64 FMA [+67%] | N-Body simulation is SIMD heavy but many memory accesses to shared data but CherryTrail still manages a 70% improvement, with Core M 70% faster still. |
|
DNBODY (GFLOPS) double/FP64 | 1.25 AVX | 1.76 AVX [+40%] | 3.71 FMA [+2.1x] | Unlike what we saw before, with FP64 code the improvement drops to 40% as with DFFT. Core M is over 2x faster still. |
| With highly optimised SIMD AVX code, we see a similar 40-100% improvement in performance; as we said before complex algorithms run a lot faster on the new Atom. With FP64 code, Core M’s FPU shows its power but at what cost? | |||||
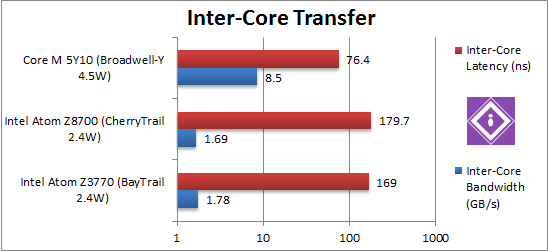 |
|||||
 |
Inter-Core Bandwidth (GB/s) | 1.63 | 1.69 [+5%] | 8.5 [+5x] | With unchanged L1/L2 caches and similar rated/Turbo clocks – it is not surprising the new Atom does not improve on inter-core bandwidth. Core M shows it’s prowess – managing over 5x higher bandwidth. We see how all these caches perform in the Cache & Memory Atom (CherryTrail) performance article. |
|
Inter-Core Latency (ns) | 182 | 179 [-6%] | 76 [-68%] | Latency, however, sees a 5% decrease, likely due to the higher clock of CherryTrail during run (due to higher rated speed) since the caches are unchanged. Core M’s latencies seem to be 1/2 (half) of Atom. |
While it does not bring any new instruction sets, CherryTrail improves significantly over the old Atom (30-100%) – much more than we’ve seen in Core series from arch to arch. It does not support new instruction sets (e.g. AVX2, FMA, SHA HWA) nor new caches – which perhaps it is just as well as Core M is not much faster.
Considering just how much BayTrail improved over the old Atom arch, the improvements are particularly impressive.
About the only “issue” is FP64 performance where Core M shows its power – whether using SIMD AVX/FMA or FPU code.
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 8.x/10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 8.1 x64 SP1, latest Intel drivers. .Net 4.5.x, Java 1.8.x. Turbo / Dynamic Overclocking was enabled on both configurations.
| VM Benchmarks | Atom Z3770 (BayTrail) | Atom X7 Z8700 (CherryTrail) | Core M 5Y10 (Broadwell-Y) | Comments | |
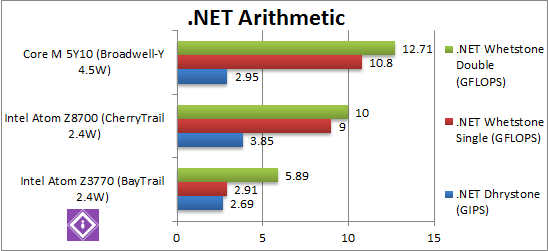 |
|||||
 |
.Net Dhrystone (GIPS) | 2.69 | 3.85 [+43%] | 2.95 [-33%] | .Net CLR performance improves by 43% – a great start and in line to what we saw with native code – again faster than Core M. |
|
.Net Whetstone final/FP32 (GFLOPS) | 2.91 | 9 [+3.1x] | 10.8 [+20%] | Floating-Point CLR performance improves by a whopping 3x (three times)! While apps should really do compute tasks in native code, this ensures that .Net (or Java) apps will fly. Core M is just 20% faster still. |
|
.Net Whetstone double/FP64 (GFLOPS) | 5.89 | 10 [+69%] | 12.71 [+27%] | FP64 CLR performance improves by a lower 70% but still great improvement. Core M’s performance improves almost 30%. |
| Just like native SIMD code, we see great improvement of 40-200% making CherryTrail significantly faster running .Net apps than old Atom. Core M is only 20-30% faster still. | |||||
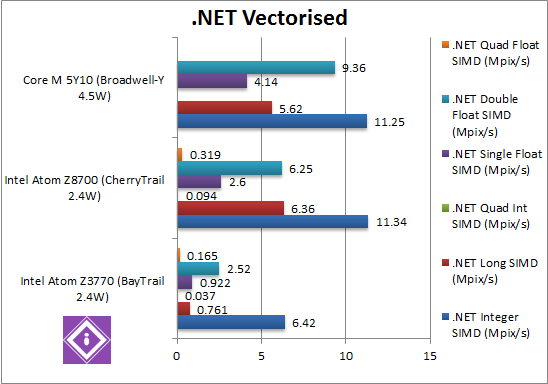 |
|||||
 |
.Net Integer Vectorised/Multi-Media (MPix/s) | 6.42 | 11.34 [+76%] | 11.25 [=] | A good start, we see vectorised .Net code a huge 76% faster in CherryTrail – even faster than Core M! |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 0.761 | 6.36 [+8.3x] | 5.62 [-12%] | With 64-bit integer vectorised workload, we see a pretty unbelievable 8x improvement – the old Atom really has an issue with this test. As before, CherryTrail is faster than Core M. |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 0.922 | 2.6 [+2.82x] | 4.14 [+59%] | Switching to single-precision (FP32) floating-point code, CherryTrail is almost 3x faster. It seems that whatever workload you have in .Net, new Atom is a good deal faster. Core M is 60% faster still. |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 2.52 | 6.25 [+2.48x] | 9.36 [+49%] | Switching to FP64 code, CherryTrail’s improvement drops to 2.5x – but Core M 50% faster still! While unlikely compute tasks are written in .Net rather than native code, small compute code does benefit. |
| Vectorised .Net improves even better, between 80-200% whether integer or floating-point workload. Unlike what we saw when we reviewed the Core CPUs, Atom does improve from arch to arch. | |||||
Just like native code, we see a huge 40-200% improvement when running .Net or Java code. Any “modern” apps (either Universal, Metro, WPF) should run very much faster – especially as heavily optimised SIMD code has also been shown to be a lot faster.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Despite being just a process shrink with minor improvements, CherryTrail is very much faster (25-100%) than the old Atom (BayTrail) within the same power envelope (TDP). Let’s not forget BayTrail itself improved greatly over the previous Atoms – thus new Atom is light-years away in performance. And that’s before we mention the very much improved EV8 GPGPU whose performance we saw earlier, see CPU Atom Z8700 (CherryTrail) GPGPU performance.
Any major CPU improvements including instruction set support (AVX2, FMA, SHA HWA) will have to wait for the next Atom arch – which should make it a formidable APU – but what we have here is still significant.
Coupled with its much improved GPGPU performance, we can now see just why Microsoft has selected it for Surface 3 – it really puts the latest Core M to shame – considering its 2x higher power rating as well as its much higher cost.
If you are after a new tablet, HTPC (like the NUC) or compute stick – best to wait for the new systems with CherryTrail – they are worth it! No ifs and no buts – these are the Atom APUs you are looking for.